Curse of dimensionality¶
Here is a function that depends on time \(t\) and 3 other parameters.
In this example class we generate many samples of the function and then try to build an interpolator that approximates this function as accurately as possible.
You can think of this function as a time series that depends on paramaters \(a,b,c\).
In this problem class, we will assume the ranges of the parameters are:
\(0<a<1\)
\(-0.5<b<0.5\)
\(5<c<10\)
When not varied we will fix the values to \(a=0.1\), \(b=-0.13\), \(c=9\).
We will always assume time \(t\) is between 0 and 1. Our time grid is t = np.linspace(0, 1, 100), unless otherwise requested.
[3]:
import numpy as np
import matplotlib.pyplot as plt
def f(t, a, b, c):
return np.sqrt(a) * np.exp(-b * t) * np.sin(c * t) + 0.5 * np.cos(2 * t)
# Example usage
# Define parameters
a = 0.1
b = -0.13
c = 9
# Define time range
t = np.linspace(0, 1, 100) # time from 0 to 1 with 100 points
# Calculate f(t) for these parameters
f_values = f(t, a, b, c)
# Plot the function
plt.figure(figsize=(10, 6))
plt.plot(t, f_values, label=r'$f(t; a, b, c)$', color='blue')
plt.xlabel('Time $t$')
plt.ylabel(r'$f(t)$')
plt.title(r'Time Series $f(t; a, b, c)$')
plt.legend()
plt.grid(True)
plt.show()
You can make a widget plot and play with different parameter values.
[4]:
from ipywidgets import interactive
import ipywidgets as widgets
def plot_with_parameters(a, b, c):
# Define time range
t = np.linspace(0, 1, 100)
# Calculate f(t) for these parameters
f_values = f(t, a, b, c)
# Plot the function
plt.figure(figsize=(10, 6))
plt.plot(t, f_values, label=r'$f(t; a, b, c)$', color='blue')
plt.xlabel('Time $t$')
plt.ylabel(r'$f(t)$')
plt.title(r'Time Series $f(t; a, b, c)$')
plt.legend()
plt.grid(True)
plt.show()
# Create interactive widget
interactive_plot = interactive(
plot_with_parameters,
a=widgets.FloatSlider(min=0, max=1, step=0.01, value=0.1),
b=widgets.FloatSlider(min=-0.5, max=0.5, step=0.01, value=-0.13),
c=widgets.FloatSlider(min=5, max=10, step=0.1, value=9)
)
display(interactive_plot)
The goal of this problem class is to sample this function across all its parameter space and create interpolators.
You should aim to understand the limitations of interpolation and how to deal with this very important problem.
Question 1¶
Consider all parameter values (except \(t\)) are fixed and create an interpolator with respect to time \(t\).
You use the original grid for the interpolation.
[5]:
t = np.linspace(0, 1, 100)
Solution¶
[6]:
from scipy.interpolate import interp1d
# Define time points and corresponding function values for a specific `a`
x = t # Time points, assumed to be defined previously
y = f_values # Function values at each time point `t` for a fixed `a`
# Create the interpolator function with respect to time `t`
F_interp_t = interp1d(x, y, kind='linear', fill_value="extrapolate")
Question 2¶
Evaluate the interpolator on a much finer grid than the original \(t\) grid.
Solution¶
[7]:
# Now you can use `F_interp_t` to interpolate the function at any time `t_new`
# Example:
t_new = np.linspace(0, 1, 1001) # An example time point within the range
f_value_at_t_new = F_interp_t(t_new) # Interpolated value at t_new
Question 3¶
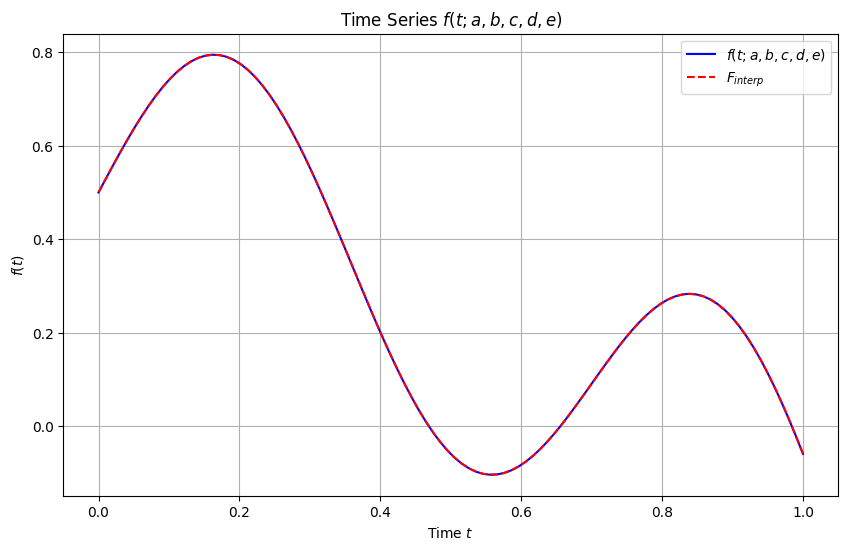
Show the results of question 2 in a plot, showing both the exact function and the predictions of the interpolator.
Solution¶
[9]:
# Plot the function
plt.figure(figsize=(10, 6))
plt.plot(t, f_values, label=r'$f(t; a, b, c, d, e)$', color='blue')
plt.plot(t_new, f_value_at_t_new, label=r'$F_{interp}$', color='red',ls='--')
plt.xlabel('Time $t$')
plt.ylabel(r'$f(t)$')
plt.title(r'Time Series $f(t; a, b, c, d, e)$')
plt.legend()
plt.grid(True)
plt.show()
Question 4¶
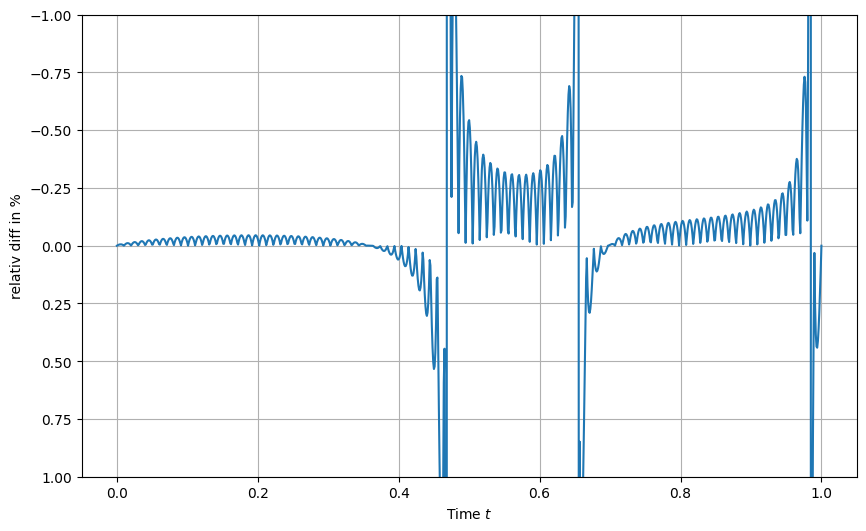
Show the ratio of the interpolated values to true values accross the fine time grid.
What do you observe? Does it make sense?
Solution¶
[11]:
# Plot the function
plt.figure(figsize=(10, 6))
r = 100*(f_value_at_t_new-f(t_new, a, b, c))/f(t_new, a, b, c)
plt.plot(t_new, r)
plt.xlabel('Time $t$')
plt.ylabel(r'relativ diff in %')
plt.ylim(1,-1)
plt.grid(True)
plt.show()
Question 5¶
Consider now all paramaters fixed except \(a\) (and \(t\)).
We assume the parameter \(a\) can take values between 0 and 1.
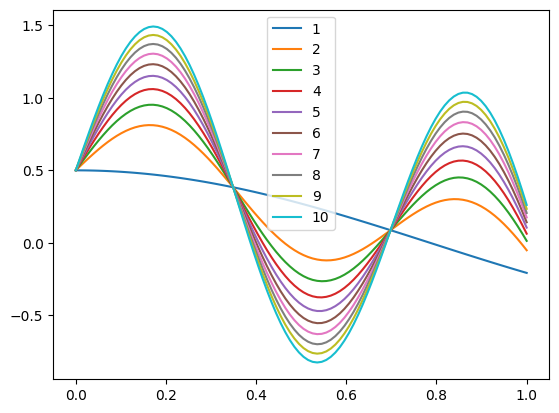
Generate 10 samples of \(f\) (i.e., 10 time series) corresponding to linearly spaced values of \(a\) spanning the interval.
Store them in a pandas DataFrame and plot them with the plot method of the DataFrame.
Solution¶
[12]:
import pandas as pd
# Generate 10 linearly spaced values of `a` from 0. to 1.0
a_values = np.linspace(0., 1.0, 10)
# Generate samples and store them in a DataFrame with labels from 1 to 10
f_samples_labeled = {str(i+1): f(t, a, b, c) for i, a in enumerate(a_values)}
f_samples_labeled_df = pd.DataFrame(f_samples_labeled, index=t)
f_samples_labeled_df
[12]:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.000000 | 0.500000 | 0.500000 | 0.500000 | 0.500000 | 0.500000 | 0.500000 | 0.500000 | 0.500000 | 0.500000 | 0.500000 |
| 0.010101 | 0.499898 | 0.530199 | 0.542750 | 0.552381 | 0.560500 | 0.567653 | 0.574120 | 0.580067 | 0.585602 | 0.590801 |
| 0.020202 | 0.499592 | 0.560023 | 0.585055 | 0.604262 | 0.620454 | 0.634720 | 0.647618 | 0.659478 | 0.670517 | 0.680886 |
| 0.030303 | 0.499082 | 0.589223 | 0.626560 | 0.655210 | 0.679363 | 0.700643 | 0.719881 | 0.737572 | 0.754038 | 0.769504 |
| 0.040404 | 0.498368 | 0.617551 | 0.666918 | 0.704799 | 0.736734 | 0.764869 | 0.790305 | 0.813696 | 0.835468 | 0.855917 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 0.959596 | -0.170695 | 0.097127 | 0.208063 | 0.293187 | 0.364950 | 0.428174 | 0.485333 | 0.537896 | 0.586821 | 0.632772 |
| 0.969697 | -0.180154 | 0.062714 | 0.163313 | 0.240505 | 0.305581 | 0.362914 | 0.414747 | 0.462413 | 0.506779 | 0.548448 |
| 0.979798 | -0.189539 | 0.026299 | 0.115702 | 0.184303 | 0.242137 | 0.293089 | 0.339154 | 0.381515 | 0.420943 | 0.457975 |
| 0.989899 | -0.198847 | -0.011895 | 0.065544 | 0.124964 | 0.175058 | 0.219191 | 0.259091 | 0.295782 | 0.329934 | 0.362010 |
| 1.000000 | -0.208073 | -0.051629 | 0.013172 | 0.062896 | 0.104815 | 0.141746 | 0.175135 | 0.205839 | 0.234417 | 0.261259 |
100 rows × 10 columns
[13]:
f_samples_labeled_df.plot(legend=True)
[13]:
<AxesSubplot: >
Question 6¶
Create an interpolator that interpolates over \(a\) (same range as previous question) and returns the full time series (i.e., values of \(f\) for all time points) over the original time grid, i.e., \(t\).
[8]:
t = np.linspace(0, 1, 100)
Plot the result for \(a=0.125\), like in question 3.
Plot the ratio, like in question 4.
Solution¶
[14]:
from scipy.interpolate import RegularGridInterpolator
# Convert the DataFrame to a 2D NumPy array with shape (len(t), len(a_values))
f_values_matrix = f_samples_labeled_df.values # Shape: (100, 10) in this example
# Create an interpolator across `a` and `t`
interpolator = RegularGridInterpolator((t, a_values), f_values_matrix, method="linear", bounds_error=False, fill_value=None)
# Define a function that interpolates over a new `a` value
def interpolate_f_over_a(new_a):
# Create a mesh of (time, new_a) points
query_points = np.array([(time, new_a) for time in t])
# Interpolate at all time points for the given new `a`
return interpolator(query_points)
[17]:
ap = 0.125
# Plot the function
plt.figure(figsize=(10, 6))
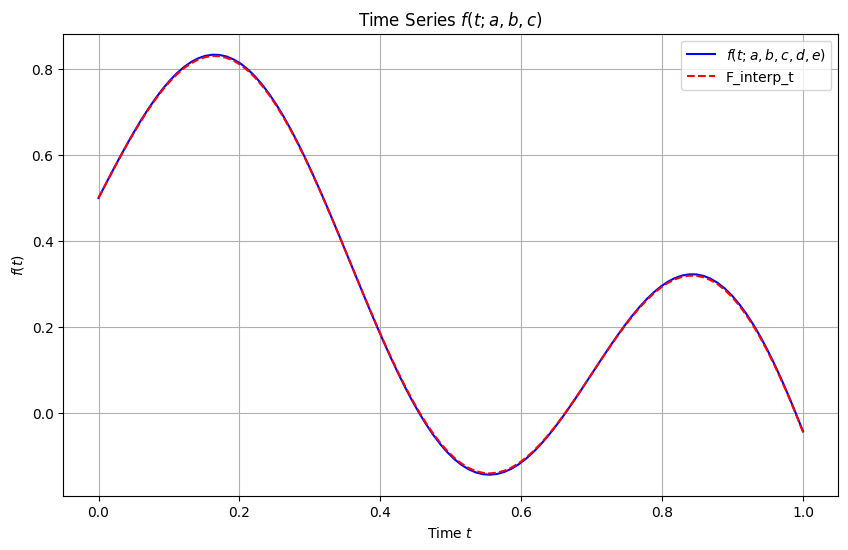
plt.plot(t, f(t, ap, b, c), label=r'$f(t; a, b, c, d, e)$', color='blue')
plt.plot(t, interpolate_f_over_a(ap), label=r'F_interp_t', color='red',ls='--')
plt.xlabel('Time $t$')
plt.ylabel(r'$f(t)$')
plt.title(r'Time Series $f(t; a, b, c)$')
plt.legend()
plt.grid(True)
plt.show()
[18]:
# Plot the function
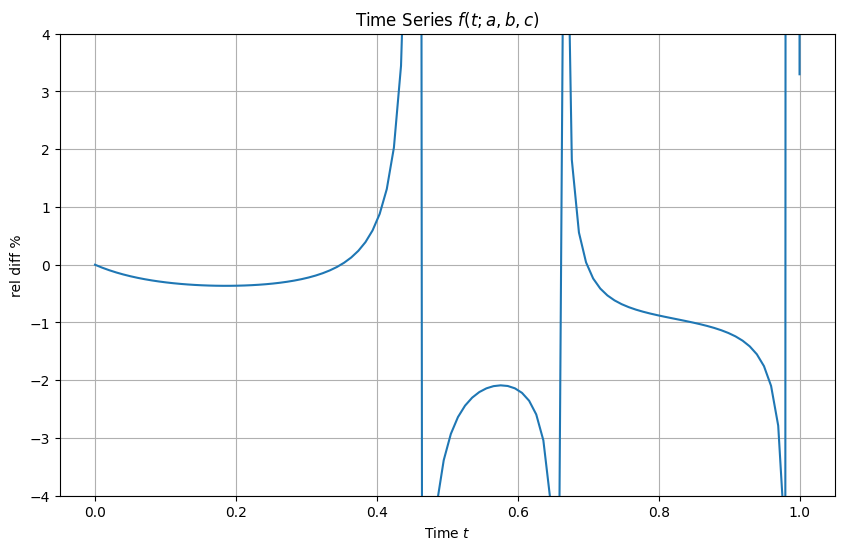
plt.figure(figsize=(10, 6))
r = 100*(interpolate_f_over_a(ap)/f(t, ap, b, c) - 1 )
plt.plot(t,r)
plt.xlabel('Time $t$')
plt.ylabel(r'rel diff %')
plt.title(r'Time Series $f(t; a, b, c)$')
plt.grid(True)
plt.ylim(-4.,4.)
plt.show()
Question 7¶
Use widgets from ipywidgets to create a sliding scale of a values.
In this question, you should plot the ratio between the interpolated values and the true values of the function evaluated at the original time grid \(t\).
Solution¶
[21]:
from ipywidgets import interact, FloatSlider
import ipywidgets as widgets
# Define the slider function to update the plot
def plot_interpolated_relative_difference(ap):
# Calculate the relative difference
r = 100 * (interpolate_f_over_a(ap) / f(t, ap, b, c) - 1.)
# Plot the relative difference
plt.figure(figsize=(10, 6))
plt.plot(t, r)
plt.xlabel('Time $t$')
plt.ylabel(r'Relative Difference %')
plt.title(r'Time Series $f(t; a, b, c)$')
plt.ylim(-10,10)
plt.grid(True)
plt.show()
# Define the slider for `ap`
ap_slider = FloatSlider(value=0.145, min=0., max=1.0, step=0.001, description='ap')
# Use `interact` to create the interactive plot
interact(plot_interpolated_relative_difference, ap=ap_slider)
[21]:
<function __main__.plot_interpolated_relative_difference(ap)>
Question 8¶
From your results of Question 7, what do you observe? Does it make sense?
Solution¶
The interpolation is now less accurate as we interpolate over a, in addition to t! All makes sense.
Question 9¶
We will now consider both \(a\) and \(b\) as interpolation parameters.
Our interpolator should therefore interpolate accross both \(a\) and \(b\) ranges.
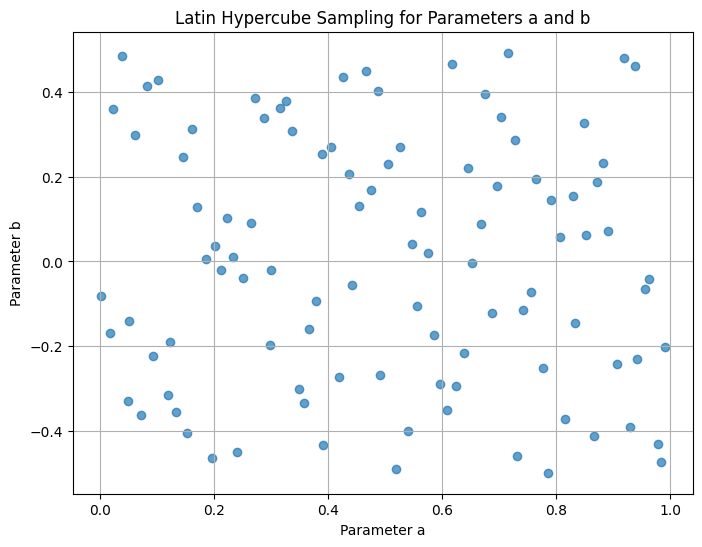
Generate \(10^2\) parameter value pairs \((a,b)\) in the range \(0<a<1\) and \(-0.5<b<0.5\) using latin hyper cube sampling.
You should use pyDOE to generate the Latin Hyper Cube samples.
You may need to pip install pyDOE to get this package, first.
Show the \(a\) and \(b\) samples as a 2D scatter plot.
Solution¶
[22]:
import numpy as np
import pandas as pd
from scipy.interpolate import RegularGridInterpolator
from pyDOE import lhs # For Latin Hypercube Sampling
# Define the ranges for `a`, `b`, and `t`
t = np.linspace(0, 1, 100) # Time range with 100 points
a_range = (0., 1.0)
b_range = (-0.5, 0.5)
# Generate Latin Hypercube samples for `a` and `b`
n_samples = 100 # Define the number of samples for each parameter
lhs_samples = lhs(2, samples=n_samples) # Latin Hypercube sampling in 2D
# Scale the samples to the range of `a` and `b`
a_values = a_range[0] + lhs_samples[:, 0] * (a_range[1] - a_range[0])
b_values = b_range[0] + lhs_samples[:, 1] * (b_range[1] - b_range[0])
[23]:
# Plot the Latin Hypercube samples as a 2D scatter plot
plt.figure(figsize=(8, 6))
plt.scatter(a_values, b_values, alpha=0.7)
plt.xlabel("Parameter a")
plt.ylabel("Parameter b")
plt.title("Latin Hypercube Sampling for Parameters a and b")
plt.grid(True)
plt.show()
Question 10¶
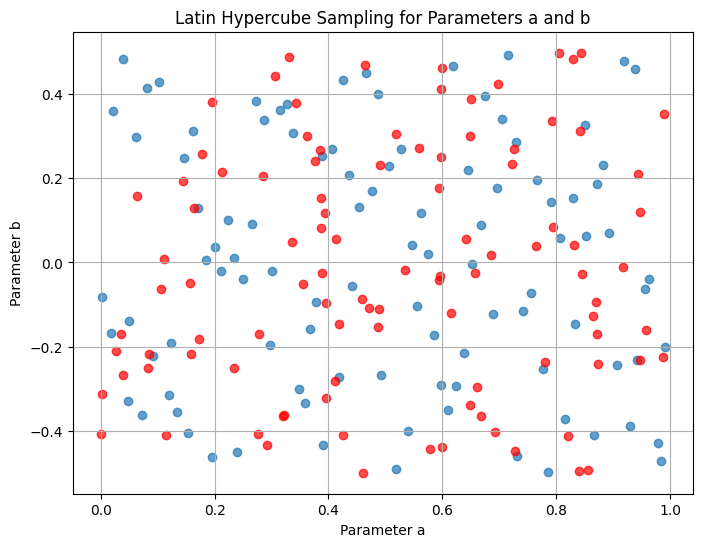
For comparison, on the same plot, add a uniformly sampled realization of \(10^2\) \(a\) and \(b\) values.
Can you distinguish by eye?
As an extension question, think of how you would proceed if you needed to prove that these samples come from different generative processes (uniform or Latin Hyper Cube).
Solution¶
[24]:
# Generate uniformly sampled values for `a` and `b`
ua_values = np.random.uniform(a_range[0], a_range[1], n_samples)
ub_values = np.random.uniform(b_range[0], b_range[1], n_samples)
# Plot the Latin Hypercube samples as a 2D scatter plot
plt.figure(figsize=(8, 6))
plt.scatter(a_values, b_values, alpha=0.7)
plt.scatter(ua_values, ub_values, alpha=0.7,c='r')
plt.xlabel("Parameter a")
plt.ylabel("Parameter b")
plt.title("Latin Hypercube Sampling for Parameters a and b")
plt.grid(True)
plt.show()
Question 11¶
Create the interpolator over the parameter space \((a,b)\), interpolating over samples of the function evaluated at the original time grid \(t\).
As you will realise, we are dealing with an irregular grid and need the griddata method (doc).
Solution¶
[26]:
t = np.linspace(0, 1, 100) # Time range with 100 points, always fixed
from scipy.interpolate import griddata
# Generate function samples for each (a, b) pair over time `t`
# Create lists to hold points and values for interpolation
points = [] # Will store (t, a, b) tuples
values = [] # Will store corresponding f(t, a, b, c) values
for a, b in zip(a_values, b_values):
for time in t:
points.append((time, a, b))
values.append(f(time, a, b, c)) # Replace `f` with your actual function definition
# Convert lists to NumPy arrays for griddata use
points = np.array(points) # Shape: (len(t) * n_samples, 3)
values = np.array(values) # Shape: (len(t) * n_samples,)
# Define a function to interpolate over new values of `a` and `b` using griddata
def interpolate_f_over_a_b(tgrid, new_a, new_b):
# Create an array of (time, new_a, new_b) points to interpolate
query_points = np.array([(time, new_a, new_b) for time in tgrid])
# Use griddata to interpolate the function at the given points
interpolated_values = griddata(points, values, query_points, method='linear')
return interpolated_values
Question 12¶
Show results with a sliding scale plot for \(a\) and \(b\).
On a different sliding bar plot, show the ratio between the interpolated values and the true values of the function evaluated at the original time grid \(t\).
What do you observe?
Does it make sense?
Solution¶
[28]:
import numpy as np
import matplotlib.pyplot as plt
from ipywidgets import interact, FloatSlider
import ipywidgets as widgets
tn = np.linspace(0, 1, 100)
# Define the interpolator function for dynamic plotting
def plot_with_interpolated_values(ap, bp):
# Original function values for given `a` and `b`
original_values = f(tn, ap, bp, c) # Replace `f` with your actual function definition
# Interpolated values for the given `a` and `b`
# interpolated_values = interpolator([(time, ap, bp) for time in tn])
interpolated_values = interpolate_f_over_a_b(tn, ap, bp)
# Plot the results
plt.figure(figsize=(10, 6))
plt.plot(tn, original_values, label=r'$f(t; a, b)$', color='blue',ls='None',marker='o')
plt.plot(tn, interpolated_values, label=r'$F_{interp}(t)$', color='red', linestyle='None',marker='o')
plt.xlabel('Time $t$')
plt.ylabel(r'$f(t)$')
plt.title(r'Time Series $f(t; a, b)$')
plt.legend()
plt.grid(True)
plt.show()
# Define sliders for `a` and `b`
a_slider = FloatSlider(value=0.125, min=0.0, max=1.0, step=0.01, description='a')
b_slider = FloatSlider(value=0.0, min=-0.5, max=0.5, step=0.01, description='b')
# Use `interact` to create the interactive plot
interact(plot_with_interpolated_values, ap=a_slider, bp=b_slider)
[28]:
<function __main__.plot_with_interpolated_values(ap, bp)>
[30]:
# Define the interpolator function for dynamic plotting
def plot_with_interpolated_values(ap, bp):
# Original function values for given `a` and `b`
original_values = f(tn, ap, bp, c) # Replace `f` with your actual function definition
# Interpolated values for the given `a` and `b`
interpolated_values = interpolate_f_over_a_b(tn, ap, bp)
# Plot the results
plt.figure(figsize=(10, 6))
plt.plot(tn, 100*(interpolated_values-original_values)/original_values, label=r'relative difference', color='red', linestyle='--')
plt.xlabel('Time $t$')
plt.ylabel(r'rel diff %')
plt.title(r'Time Series $f(t; a, b, c)$')
plt.legend()
plt.ylim(-2,2)
plt.grid(True)
plt.show()
# Define sliders for `a` and `b`
a_slider = FloatSlider(value=0.125, min=0.0, max=1.0, step=0.01, description='a')
b_slider = FloatSlider(value=0.0, min=-0.5, max=0.5, step=0.01, description='b')
# Use `interact` to create the interactive plot
interact(plot_with_interpolated_values, ap=a_slider, bp=b_slider)
[30]:
<function __main__.plot_with_interpolated_values(ap, bp)>
Interpolation is now even harder (memory, accurracy, compute time, etc) and much less accurate. We start to see the real effects of curse of dimensionality!
Question 13¶
Compare memory and time of (i) the original function call and (ii) the interpolator call.
Comment.
Solution¶
[32]:
import numpy as np
import tracemalloc
import timeit
# Define the time array `tn`
tn = np.linspace(0, 1, 100) # Increase number of points for the test
ap = 0.125 # Fixed values for parameters
bp = 0.1
c, d, e = 1.0, 1.0, 1.0 # Fixed parameters for `f`
# Define a wrapper function to measure the original function call
def original_function_call():
return f(tn, ap, bp, c) # Replace `f` with your actual function definition
# Define a wrapper function to measure the interpolator call
def interpolator_call():
return interpolate_f_over_a_b(tn, ap, bp)
# Measure time
time_original = timeit.timeit(original_function_call, number=10)
time_interpolator = timeit.timeit(interpolator_call, number=10)
# Measure memory using tracemalloc
def measure_memory(func):
tracemalloc.start()
func() # Run the function to allocate memory
current, peak = tracemalloc.get_traced_memory()
tracemalloc.stop()
return peak / (1024 * 1024) # Memory in MB
memory_original = measure_memory(original_function_call)
memory_interpolator = measure_memory(interpolator_call)
# Print results
print(f"Original function call time (10 runs): {time_original:.4f} seconds")
print(f"Interpolator call time (10 runs): {time_interpolator:.4f} seconds")
print(f"Original function call memory usage: {memory_original:.4f} MB")
print(f"Interpolator call memory usage: {memory_interpolator:.4f} MB")
Original function call time (10 runs): 0.0002 seconds
Interpolator call time (10 runs): 3.9441 seconds
Original function call memory usage: 0.0027 MB
Interpolator call memory usage: 10.8302 MB
Numbers make sense, with respect to what we explain about curse of dimensionality!
Question 14¶
Add a third parameter, \(c\) to our interpolation problem and repeat questions 9 to 13.
For this parameter, use a range of \(5<c<10\).
Comment on the results.
Solution¶
[33]:
import numpy as np
import pandas as pd
from scipy.interpolate import RegularGridInterpolator
from pyDOE import lhs # For Latin Hypercube Sampling
# Define the ranges for `a`, `b`, and `t`
t = np.linspace(0, 1, 100) # Time range with 100 points
a_range = (0., 1.0)
b_range = (-0.5, 0.5)
c_range = (5, 10)
# Generate Latin Hypercube samples for `a` and `b`
n_samples = 100 # Define the number of samples for each parameter
lhs_samples = lhs(3, samples=n_samples) # Latin Hypercube sampling in 2D
# Scale the samples to the range of `a` and `b`
a_values = a_range[0] + lhs_samples[:, 0] * (a_range[1] - a_range[0])
b_values = b_range[0] + lhs_samples[:, 1] * (b_range[1] - b_range[0])
c_values = c_range[0] + lhs_samples[:, 2] * (c_range[1] - c_range[0])
[34]:
# Plot the Latin Hypercube samples in 3D
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
sc = ax.scatter(a_values, b_values, c_values, c=a_values, cmap='viridis', marker='o', alpha=0.7)
# Set plot labels and title
ax.set_xlabel('Parameter a')
ax.set_ylabel('Parameter b')
ax.set_zlabel('Parameter c')
ax.set_title('3D Latin Hypercube Sampling for Parameters a, b, and c')
[34]:
Text(0.5, 0.92, '3D Latin Hypercube Sampling for Parameters a, b, and c')
[35]:
t = np.linspace(0, 1, 100) # Time range with 100 points, always fixed
from scipy.interpolate import griddata
# Generate function samples for each (a, b) pair over time `t`
# Create lists to hold points and values for interpolation
points = [] # Will store (t, a, b) tuples
values = [] # Will store corresponding f(t, a, b, c, d, e) values
for a, b, c in zip(a_values, b_values,c_values):
for time in t:
points.append((time, a, b, c))
values.append(f(time, a, b, c)) # Replace `f` with your actual function definition
# Convert lists to NumPy arrays for griddata use
points = np.array(points) # Shape: (len(t) * n_samples, 3)
values = np.array(values) # Shape: (len(t) * n_samples,)
# Define a function to interpolate over new values of `a` and `b` using griddata
def interpolate_f_over_a_b_c(tgrid, new_a, new_b, new_c):
# Create an array of (time, new_a, new_b) points to interpolate
query_points = np.array([(time, new_a, new_b, new_c) for time in tgrid])
# Use griddata to interpolate the function at the given points
interpolated_values = griddata(points, values, query_points, method='linear')
return interpolated_values
[37]:
import numpy as np
import matplotlib.pyplot as plt
from ipywidgets import interact, FloatSlider
import ipywidgets as widgets
tn = np.linspace(0, 1, 100)
# Define the interpolator function for dynamic plotting
def plot_with_interpolated_values(ap, bp, cp):
# Original function values for given `a` and `b` and `c`
original_values = f(tn, ap, bp, cp) # Replace `f` with your actual function definition
# Interpolated values for the given `a` and `b` and `c`
interpolated_values = interpolate_f_over_a_b_c(tn, ap, bp, cp)
# Plot the results
plt.figure(figsize=(10, 6))
plt.plot(tn, original_values, label=r'$f(t; a, b, c)$', color='blue', linestyle='None',marker='o')
plt.plot(tn, interpolated_values, label=r'$F_{interp}(t)$', color='red', linestyle='None',marker='o')
plt.xlabel('Time $t$')
plt.ylabel(r'$f(t)$')
plt.title(r'Time Series $f(t; a, b, c)$')
plt.legend()
plt.grid(True)
plt.show()
# Define sliders for `a` and `b`
a_slider = FloatSlider(value=0.125, min=0.0, max=1.0, step=0.01, description='a')
b_slider = FloatSlider(value=0.0, min=-0.5, max=0.5, step=0.01, description='b')
c_slider = FloatSlider(value=6, min=5, max=10, step=0.01, description='c')
# Use `interact` to create the interactive plot
interact(plot_with_interpolated_values, ap=a_slider, bp=b_slider, cp=c_slider)
[37]:
<function __main__.plot_with_interpolated_values(ap, bp, cp)>
[38]:
# Define the interpolator function for dynamic plotting
def plot_with_interpolated_values(ap, bp, cp):
# Original function values for given `a` and `b`
original_values = f(tn, ap, bp, cp) # Replace `f` with your actual function definition
# Interpolated values for the given `a` and `b`
interpolated_values = interpolate_f_over_a_b_c(tn, ap, bp, cp)
# Plot the results
plt.figure(figsize=(10, 6))
plt.plot(tn, 100*(interpolated_values-original_values)/original_values, label=r'relative difference', color='red', linestyle='--')
plt.xlabel('Time $t$')
plt.ylabel(r'rel diff %')
plt.title(r'Time Series $f(t; a, b, c)$')
plt.legend()
plt.ylim(-2,2)
plt.grid(True)
plt.show()
# Define sliders for `a` and `b`
a_slider = FloatSlider(value=0.125, min=0.0, max=1.0, step=0.01, description='a')
b_slider = FloatSlider(value=0.0, min=-0.5, max=0.5, step=0.01, description='b')
c_slider = FloatSlider(value=9, min=5, max=10, step=0.01, description='c')
# Use `interact` to create the interactive plot
interact(plot_with_interpolated_values, ap=a_slider, bp=b_slider, cp=c_slider)
[38]:
<function __main__.plot_with_interpolated_values(ap, bp, cp)>
[40]:
import numpy as np
import tracemalloc
import timeit
# Define the time array `tn`
tn = np.linspace(0, 1, 100) # Increase number of points for the test
ap = 0.125 # Fixed values for parameters
bp = 0.1
cp = 9.
d, e = 1.0, 1.0 # Fixed parameters for `f`
# Define a wrapper function to measure the original function call
def original_function_call():
return f(tn, ap, bp, cp) # Replace `f` with your actual function definition
# Define a wrapper function to measure the interpolator call
def interpolator_call():
return interpolate_f_over_a_b_c(tn, ap, bp, cp)
# Measure time
time_original = timeit.timeit(original_function_call, number=100)
time_interpolator = timeit.timeit(interpolator_call, number=1)
# Measure memory using tracemalloc
def measure_memory(func):
tracemalloc.start()
func() # Run the function to allocate memory
current, peak = tracemalloc.get_traced_memory()
tracemalloc.stop()
return peak / (1024 * 1024) # Memory in MB
memory_original = measure_memory(original_function_call)
memory_interpolator = measure_memory(interpolator_call)
# Print results
print(f"Original function call time (100 runs): {time_original:.4f} seconds")
print(f"Interpolator call time (1 runs): {time_interpolator:.4f} seconds")
print(f"Original function call memory usage: {memory_original:.4f} MB")
print(f"Interpolator call memory usage: {memory_interpolator:.4f} MB")
Original function call time (100 runs): 0.0022 seconds
Interpolator call time (1 runs): 5.2599 seconds
Original function call memory usage: 0.0027 MB
Interpolator call memory usage: 65.9616 MB
Question 15¶
Instead of interpolating with the griddata method, use (i) a gaussian process, and (ii) a neural network whose output layer is the function predicted at the \(10^2\) points of the time grid and input layer is \(a,b,c\) values.
What do you observe in terms of (i) time and (ii) memory? Comment on scalability in all cases covered.
Tips: For the neural net part of this question use Google Colab and the GPUs there. Training should take a few minutes. A good idea for you to practice is also to use CSD3 to solve this question.
Solution¶
Gaussian Process
[41]:
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF, ConstantKernel as C
# Define a Gaussian Process model with an RBF kernel
kernel = C(1.0) * RBF(length_scale=[1.0, 1.0, 1.0, 1.0])
gp = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=10, alpha=1e-3)
[28]:
# Train the GP model
gp.fit(points, values)
[28]:
GaussianProcessRegressor(alpha=0.001,
kernel=1**2 * RBF(length_scale=[1, 1, 1, 1]),
n_restarts_optimizer=10)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GaussianProcessRegressor(alpha=0.001,
kernel=1**2 * RBF(length_scale=[1, 1, 1, 1]),
n_restarts_optimizer=10)[29]:
# Define the interpolation function using the trained GP
def interpolate_f_over_a_b_c_gp(tgrid, new_a, new_b, new_c):
# Prepare query points
query_points = np.array([(time, new_a, new_b, new_c) for time in tgrid])
# Predict using the GP model
interpolated_values, _ = gp.predict(query_points, return_std=True)
return interpolated_values
[31]:
# Define a wrapper function to measure the interpolator call
def interpolator_gp_call():
return interpolate_f_over_a_b_c_gp(tn, ap, bp, cp)
[32]:
time_interpolator_gp = timeit.timeit(interpolator_gp_call, number=1)
print(f"Interpolator call time (1 runs): {time_interpolator_gp:.4f} seconds")
Interpolator call time (1 runs): 0.2925 seconds
[34]:
memory_interpolator_gp = measure_memory(interpolator_gp_call)
print(f"Interpolator call memory usage: {memory_interpolator_gp:.4f} MB")
Interpolator call memory usage: 30.5227 MB
Neural net solution provided in this Colab notebook.
Note on Gaussian Process vs Neural Net¶
Gaussian Process (GP) Interpolation
Gaussian Processes are a probabilistic model for regression that can handle multi-dimensional interpolation. They are particularly useful when the function is smooth and continuous.
Prepare Training Data: Use your
(t, a, b, c)points as inputs and the function values as outputs.Train a Gaussian Process Regressor.
Use the Trained GP for Interpolation.
Explanation of the Gaussian Process Code
Kernel: We use an RBF (Radial Basis Function) kernel, which is commonly used for smooth interpolation tasks. The
length_scalecontrols the smoothness along each dimension.Training the GP: The GP model is trained on the
(t, a, b, c)points with corresponding function values.Interpolating:
interpolate_f_over_a_b_c_gpuses the trained GP to interpolate over new values ofa,b, andc.
Method |
Pros |
Cons |
|---|---|---|
Gaussian Process |
Provides uncertainty estimates; works well for smooth, continuous functions |
Slower for large datasets; memory-intensive |
Neural Network |
Scales well to large datasets; works for complex, non-linear functions |
No uncertainty estimates; requires more data for training stability |
Choose the method based on the size of your dataset and the nature of your function f. Gaussian Processes are typically best for small to moderate-sized datasets with smooth functions, while neural networks are better for larger datasets or more complex functions.
Note on Latin Hyper Cube sampling¶
Why not using uniform sampling?
No, Latin Hypercube Sampling (LHS) is not the same as uniform (random) sampling. While both methods aim to sample points across a parameter space, they differ in how they distribute those points, especially in higher dimensions.
Stratification:
Latin Hypercube Sampling divides the range of each parameter into equal intervals and ensures that each interval is sampled exactly once. This helps LHS achieve a more uniform distribution across the parameter space by avoiding clusters and ensuring coverage across all intervals.
Uniform (Random) Sampling, on the other hand, does not enforce such stratification, so points can cluster together or leave large gaps in the parameter space.
Dimensional Coverage:
LHS is particularly effective in high-dimensional spaces because it ensures each sampled point covers different parts of each dimension.
Uniform Sampling lacks this structured approach, so some dimensions may not be as well-covered, especially with a limited number of samples.
Sample Distribution:
With LHS, each row and each column in a 2D sampling grid (or each “slice” in higher dimensions) contains exactly one sample point. This constraint leads to a better spread of points.
Uniform Sampling does not have this constraint, which can lead to points overlapping or clustering in certain areas.
In a 2D plot: - LHS will ensure that each interval along both the a and b axes is sampled once, leading to a “grid-like” distribution. - Uniform Sampling will scatter points without ensuring they appear in every interval, so it may result in some intervals having multiple points while others have none.