17. Multi-Agent Systems for Data Science¶
We introduce the concept of agents, Multi-Agent Systems (MAS), and illustrate the potential of such systems in automating data science tasks, such as software development or data analysis. We use OpenHands as our agentic software development example. For an example of multi-agent systems for cosmological data analysis, see cmbagent.
Useful references include:
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation Framework, Wu et al (2023)
OpenHands: An Open Platform for AI Software Developers as Generalist Agents, Wang et al (2024)
Multi-Agent System for Cosmological Parameter Analysis, Laverick et al (2024)
17.1. Agency¶
The English language has a great word (that doesn’t exist in French): agency.
It means the ability to act.
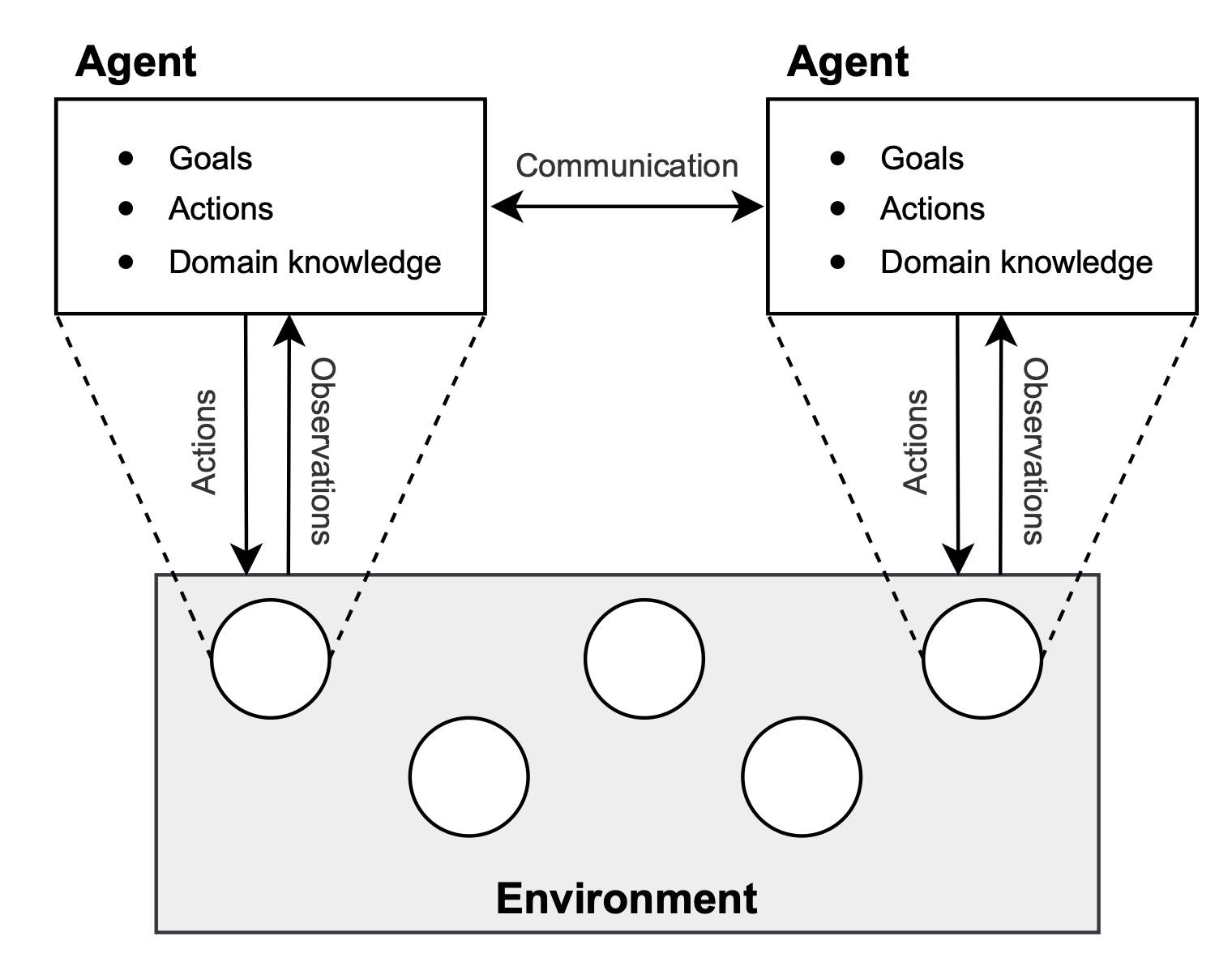
Figure from the marl book.
The figure above illustrates the concept of agency in multi-agent systems. There are two agents, that make observations and act on a joint environment.
The particularity of agentic AI systemsis that the environment is acted upon, it changes. This is different from other types of AI systems you have seen so far for two reasons:
The environment is static and only the model is updated.
Once the model has been trained, the tasks that the model performs generally output an information that is completely seperate from the environment.
For instance, when you train a neural network, the training data is fixed and only the weights and biases of the network are updated during learning/training. When you evaluate the network, the input data is also not changed but it simply output a prediction that lives somewhere else than the input data.
When training a MAS, both the system and environment are updated. Moreover, from the perspective of each agent in the system, the environment is changed by the actions of the other agents. This is called non-stationarity.
To understand this, take the example of a MAS for software development. The environment is the code base of the project. Agents can write, add, remove, modify, execute code. The environment, i.e., the code base, is changed by the actions of the agents. Training such a MAS means finding best communication protocols between agents, and for each agent the best instructions to follow, to successfully develop software that should be optimal in the sense that it meets the project requirements and some software quality metrics. Once the MAS is trained, it should be able to develop similar software by itself, optimally.
17.2. Reinforcement Learning Basics¶
Training a MAS is based on the principles of Reinforcement Learning (RL). There is a direct parallel between RL and Game Theory.
Let us introduce important concepts. As in other types of learnig, RL is dynamic and we use the notion of time step \(t\).
Environment: The environment is what the agents interact with. It is denoted by \(\mathcal{E}\). The interactions between the agents and the environment occur over a number of discrete time steps.
State: At each time step \(t\), an agent receives a state \(s_t\). The set of possible states is denoted by \(\mathcal{S}\).
Action: According to its policy, the agent in state \(s_t\) chooses an action \(a_t\) to take. The set of possible actions is denoted by \(\mathcal{A}\).
Policy: The policy is the mapping from states to actions:
It is a strategy. It assigns probabilities to the available actions in each state.
After an action is taken, the agent receives the next state \(s_{t+1}\).
Reward: The reward is a scalar value computed at each time step, indicating how good or bad the agent’s last action was in achieving its goals. It is the feedback that the agent receives, to learn and improve its behavior (i.e., its policy) over time.
For a one agent, the reward \(r_t\) at time \(t\) is defined as:
where:
\(s_t \in \mathcal{S}\): The state of the environment at time \(t\).
\(a_t \in \mathcal{A}\): The action taken by the agent at time \(t\).
\(s_{t+1} \in \mathcal{S}\): The next state of the environment after taking action \(a_t\).
The reward function \(R: \mathcal{S} \times \mathcal{A} \times \mathcal{S} \to \mathbb{R}\) maps the current state, action, and next state to a real number (the reward).
For example, consider an agent controlling a robot trying to navigate a grid to reach a goal:
States (\(\mathcal{S}\)): The robot’s position on the grid.
Actions (\(\mathcal{A}\)): {Up, Down, Left, Right}.
Reward (\(R\)):
\(+10\): If the robot reaches the goal state.
\(-1\): For each move (to encourage efficiency).
\(-100\): If the robot collides with an obstacle.
If the robot is at position \((1, 1)\), moves “Right” to \((1, 2)\), and hits an obstacle, the environment provides a reward \(r_t = -100\).
Markov decision process (MDP): The standard model to define the environment in which the agent chooses actions over a number of time steps.
Useful references:
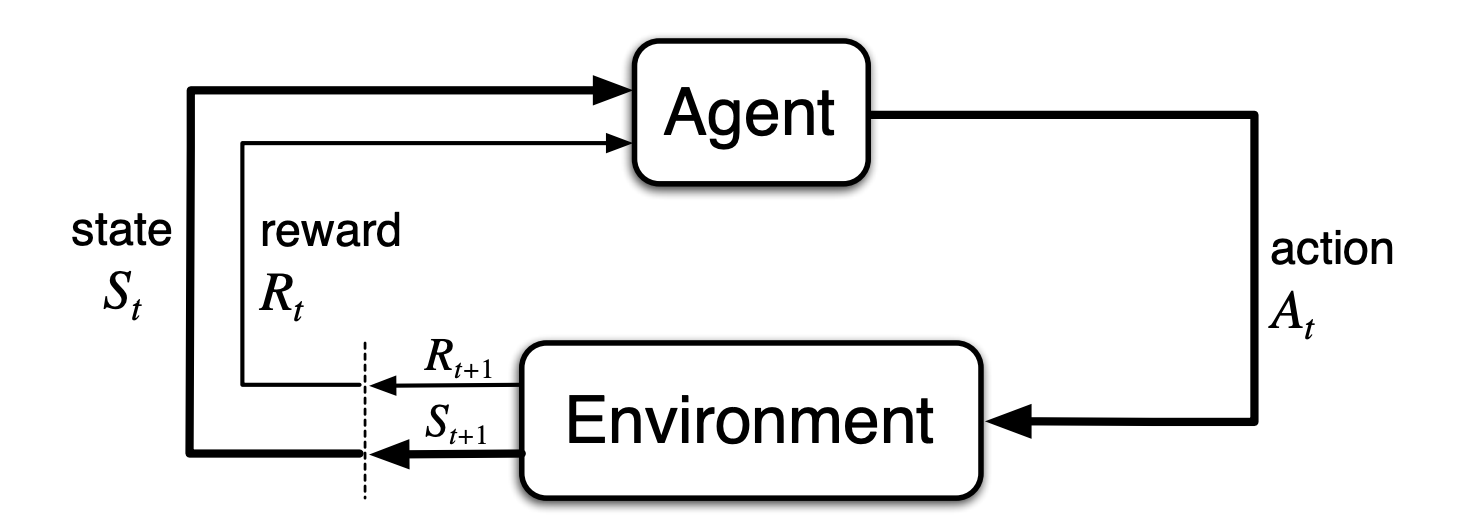
Figure from Sutton and Barto (2020). Basic RL loop for a 1-agent system.
17.3. Deep Reinforcement Learning¶
Useful references:
A pilot course on deep RL may be offered in the second semester (see with Boris Bolliet for details)